FSI-Zimmer: offen
Du befindest dich hier: FSI Informatik » Prüfungsfragen und Altklausuren » Prüfungen im Bachelor-Studium (1. - 5. Semester) » pfp » Aufgabe 1 (Übersicht)
Aufgabe 1
- a) Sequentieller Umstieg, Beschränkung der Parallelität.
- b) Das Schalten einer Transition erfolgt atomar. Es gilt: P-Überdeckung ⇒ Beschränkt. Lebendig && Beschränkt ⇒ T-Überdeckung. Aus P- & T-Überdeckung kann man daher keine Lebendigkeit folgern.
- c) Die parallale Effizienz ist 2. Der Speedup ist 16.
Aufgabe 2
Block 1
new CyclicBarrier(nThreads);
Block 2
// Lösung mit einzelnen Thread-Objekten auch denkbar
ExecutorService es = Executors.newFixedThreadPool(nThreads);
for (int i = 0; i < nThreads; i++) {
GRunnable gr = new GRunnable(i, nThreads, barrier);
es.execute(gr),
}
Block 3
es.shutdown(); es.awaitTermination(60, TimeUnit.SECONDS);
Block 4
for (int col = id; col < size; col += nThreads) {
for (int row = 0; row < size; row++) {
dest[row][col] = step(row, col);
}
}
Block 5
if (barrier.await() == 0) { // alternativ auch barrier.await() und dann if (id == 0)
swap();
}
barrier.await();
Block 6
// Beabsichtigt leer gelassen // Falls in 1 new CyclicBarrier(nThreads + 1) und im Mainthread in 3 mittels barrier.await() synchronisiert wird, muss hier auch ebarrier.await() stehen.
Aufgabe 3
- a)
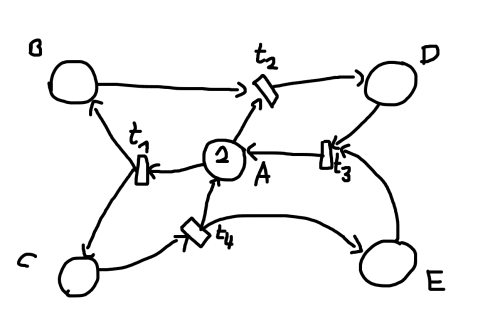
- b) Ein Pfeil von Q zu t1 (Gewicht 1) und ein Pfeil von t2 zu Q (Gewicht 2). Desweiteren muss noch verhindert werden, dass t3 schalten und somit unendlich viele Marken generieren kann. Dazu ist z.B. eine Kante von Q zu t3 mit dem Gewicht 3 nötig.

Aufgabe 4
- a)
- Zeile 27: Nein, weil AtomicInteger zwar intern synchronisiert ist, der Wert aber mit eienm anderen verglichen wird, wodurch eine Prüfe-Handle-Situation entsteht.
- Zeile 34: Ja, weil jeder Thread nur die lokale Variable modifiziert und synchronized(this) eh sinnlos ist.
- Zeile 38: Nein, globalHits ist allen Threads gemein ⇒ sonst Lesen-Ändern-Schreiben-Wettlaufsituation.
- b)
- 14/46: Nein, weil i in #47 zur Berechnung benötigt wird. D.h. man benötigt sowohl Datensichtbarkeit (wäre mit volatile auch möglich) als auch zeitliche Synchronisation (nur dank barrier.await() hier möglich).
- 19/49: Ja, da v eine volatile Referenz ist und Spin (= aktives Warten) existent. (Die volatile-Deklaration verhindert, dass ein Objekt bei Zugriff noch nicht vollständig initialisiert ist.)
- 22/52: Laut Tutor soll man jede Barriere einzeln betrachten. Wir gehen also davon aus, dass die Barriere 19/49 immer noch existent ist. Dann gilt k=-1 sicher in Zeile 50 in Thread 3. Es ist jedoch nicht garantiert, dass wir jemals den neuen Wert aus Zeile 21 in Thread 3 auslesen werden, da k nicht volatile ist. Daher entweder k volatile deklarieren oder die Barriere dort lassen (⇒ Antwort „Nein“).
- 22/52: Begründung unter Annahme, dass 19/49 bereits gestrichen wurde: Nein, denn in Thread 3 könnte k=0 (Default-Wert bei Instanzinitialisierung der „echten“ Barrier-Klasse aus Zeile 2) aufgrund fehlender Synchronisationspunkte bei der While-Schleife in #53 gelten ⇒ Falsche Ausgabe.
Aufgabe 5
def aliveNeighbors: (Cell => List[Cell]) => Cell => Int = f => cell => f(cell).count(_.alive) def tick: Field => Field = field => field.map(cell => aliveNeighbors(neighbors(field))(cell) match { case n i f(n < 2 || n > 3) => Cell(cell.x, cell.y, false) case 3 => Cell(cell.x, cell.y, true) case default => cell }) def game: Field => Stream[Field] = f => f #:: game(tick(f))
Aufgabe 6
- a)
def first: List[Solution] => Solution = sols => // alternativ sols.foldLeft(Nil: List[Transition)... sols.foldLeft(List[Transition]())((acc, cur) => acc match { case Nil => cur case default => acc })
- b) Das Kopfelement ist immer das aktuell zu bearbeitende Element. Der Rest der Liste entspricht den bereits besuchten Zuständen.
case (s::ss, sol) if s == end => sol case (s::ss, sol) if ss.contains(s) => Nil case (s::ss, sol) => { val next = passage(s) first(next.map({ case (nextState, nextTransition) => helper(nextState::s::ss, sol ::: List(nextTransition)) })) }