Disclaimer: Dieser Thread wurde aus dem alten Forum importiert. Daher werden eventuell nicht alle Formatierungen richtig angezeigt. Der ursprüngliche Thread beginnt im zweiten Post dieses Threads.
KI2 - Neuronale Netze Turnier - Info
Heyho zusammen,
die Vorbereitungen sind beinahe abgeschlossen. Die Website (wenn auch Designtechnisch bescheiden gehalten :D) ist fertig und funktionsbereit.
Die Datensätze stehen auch fest und zwei können bereits eingelesen werden.
Morgen (Freitag) werde ich die fehlenden Methoden für den dritten Datensatz ebenso wie ein „einfaches“ raus schreiben der Daten in das entsprechende Format einbauen.
Morgen ab 20:15 werde ich auf jeden Fall die Datensätze hochladen auf StudOn (mindesten 2 von 3), falls sie nicht die Datei-Begrenzungen sprengen.
Haben wir jetzt folgende drei Datensätze zum rumspielen. Wobei ein Datensatz wahrscheinlich euch und auch eure Computer an den Rand des Wahnsinns treiben wird. ![]()
Soweit zu den Datensätzen, jetzt will ich euch noch kurz auf dem Laufendem halten was die Vorlesung/Übung am Montag/Mittwoch/Donnerstag angeht.
Montag will ich auf jeden Fall mindestens 45min in „Deep Learning“, „Ideen“ und „Coole Anwendungsgebiete/Umsetzung“ investieren. Die restlichen 45min bin ich dann offen für Fragen oder alternativ wir machen noch ein bisschen mit den DeepLearning-Folien weiter. Das hängt ganz von euch ab. ![]()
Die restlichen Tage hängen dementsprechend auch von euch ab. Ich freu mich, wenn jemand Lust hat ein paar Ideen zu teilen (egal ob vor allen oder nur „privat“ zu mir), ansonsten machen wir da auch „DeepLearning-Vorlesung“. Soweit ich weiß wird das auch auf Video aufgenommen, aber da ich hauptsächlich euch helfen will bzw. mit euch interagieren will, lohnt es sich (eventuell) persönlich vorbei zu kommen.
Wie letztes Semester wird es für die Sieger (ich denke wieder Top 3) auch Bonuspunkte geben. Ob wir alle 3 Datensätze „irgendwie“ zusammenrechnen oder ob die Sieger der jeweiligen Datensätze „gesondert Punkte kriegen“ ist noch offen. Dazu hab ich bisher noch keine Idee, notfalls beuge ich mich der Demokratie! ![]()
Damit ein Echtzeit-Vergleich möglich ist, bekommt jeder dasselbe Testset und Trainingsset. Der Clou ist aber, dass um herauszufinden wie gut eure Predictions sind, ihre eure Testdaten-Ergebnisse hochladen müsst. Das heißt ihr seid in Echtzeit darüber informiert wo ihr steht und wer euch wann bzw. wie überholt hat. Dazu habe ich heute ein kleines Online-Scoreboard gebaut, einen Screenshot gibt es auch direkt:
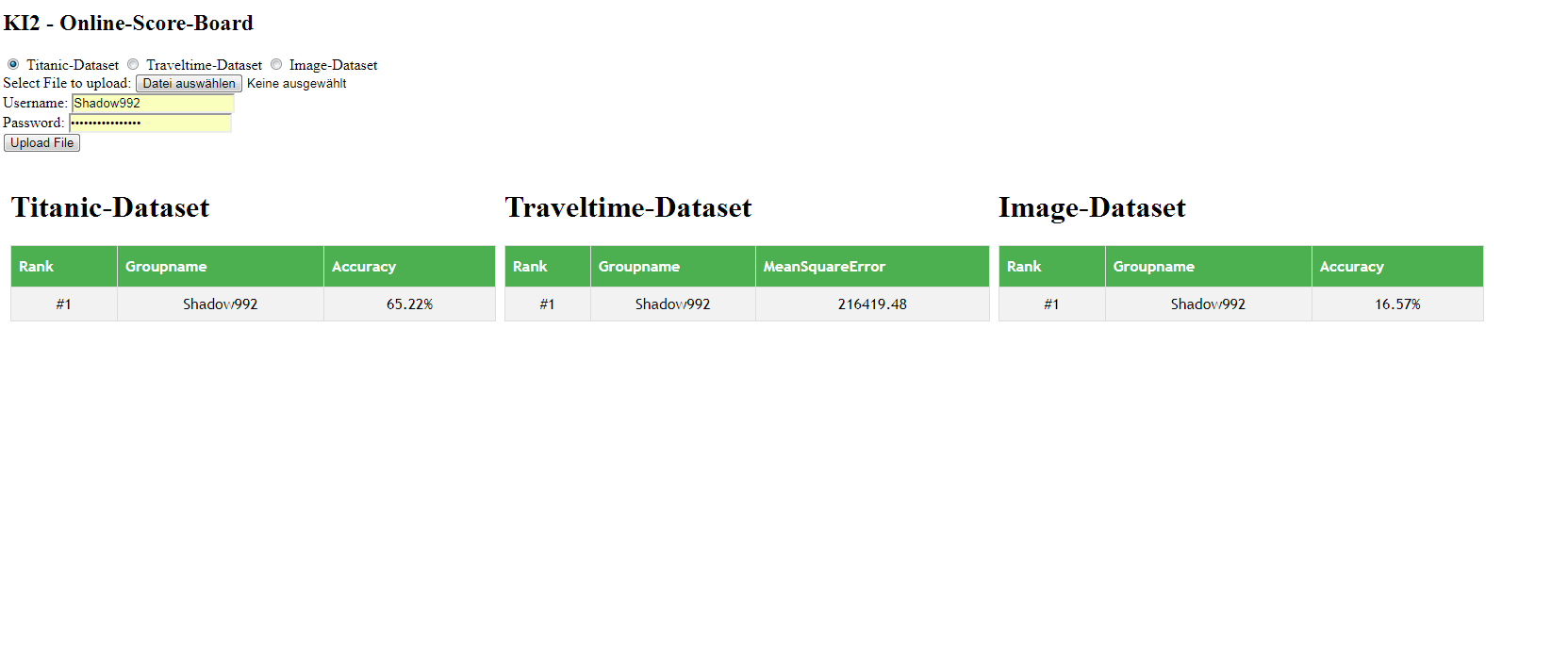
(Wenn jemand Lust hat das noch etwas aufzuhübschen, nur zu, ich hab nichts dagegen
WICHTIG: Da ich die Seite nicht mit zusätzlichen Sicherheitsabfragen (wie etwas Kurs-Passwort o.ä.) versehen habe, kann prinzipiell jeder darauf zugreifen. Das ist aber natürlich nur semi-optimal, weswegen ich die URL zum Online-Score-Board bei offiziellem Turnierbeginn als E-Mail rumschicken werde.
Das klingt nach einer coolen Challenge.
Aber wenn wir die Testdaten bekommen, was hindert einen beim dritten Datensatz daran händisch die richtigen Werte abzulesen und abzugeben?
1 „Gefällt mir“
Das kannst du machen, genau deswegen gibt es für jeden Datensatz einen 3. geheimen Test-Datensatz, der dann über die Gewinner entscheidet. Das heißt selbst wenn ihr beim letzten Datensatz die Bilder per Hand durchgeht (sind btw. 10k Testbilder :D), seid ihr lediglich bei dem Online-Scoreboard ganz oben. Aber das secret Test-Set bleibt davon völlig unberührt. ![]() Das bringt auch etwas Spannung in das Ganze, weil man sich nie 100% sicher sein kann, dass man wirklich gewinnt, wenn man im Public-Scoreboard ganz oben steht.
Das bringt auch etwas Spannung in das Ganze, weil man sich nie 100% sicher sein kann, dass man wirklich gewinnt, wenn man im Public-Scoreboard ganz oben steht. ![]()
Achso, heißt das ihr lasst unseren Code dann nach Abgabetermin nochmal über das “secret” Testset laufen? Dürfen wir dann vortrainierte Gewichte abgeben oder lasst ihr es eine von uns vordefinierte Architektur trainieren?
Wenn ihr unseren Code ausführt, wie schaut es aus mit
- Multithreading?
- Grafikkarte?
- Dürfen wir libs verwenden oder nicht verwenden?
- Gibt es Punktabzug, wenn ich mein Netz mit Tensorflow trainiere und nur die Gewichte in die Java-Implementierung einlese?
1 „Gefällt mir“
Ihr dürft den Code nochmal über das „secret“ Datenset laufen lassen (aber mit sehr beschränkter Zeit 1-2 tage). Dementsprechend könnt ihr auch theoretisch jede Programmiersprache nehmen, die ihr wollt. Aber euch muss klar sein, dass es mit Hilfe u.ä. von mir dann (vorausgesetzt es ist nicht C++ :D) Mau aussieht. Die Gewinner werden dann aber logischerweise nachweisen müssen, dass ihr Code wirklich das produziert, was sie hochgeladen haben. Sprich da wird es dann eine manuelle Inspektion geben.
Multithreading ist definitiv erlaubt, aber bringt, abgesehen von kürzeren Trainingszeiten eh nichts. Ist also die Frage, ob man sich das antun will für statt 30min Training dann 10min Training. Grafikkarte ist demnach auch erlaubt.
Libs dürfen nicht verwendet werden, die nicht im Standard dabei sind. Das heißt besonders KEIN scikit-learn oder ähnliches.
Prinzipiell kannst du es auch in Tensorflow trainieren, denn damit du die Gewichte dann sinnvoll benutzen kannst in deinem Framework, musst du natürlich möglichst 1:1 Tensorflow nachbauen. Das kannst du schon einmal probieren, ich zweifle aber extrem an, dass das „effektiver“ (im Sinne von Preis/Leistung) ist als es direkt in Java zu trainieren. Die Datensätze sind echt nicht gigantisch, da lohnt es sich kaum auf Grafikkarten o.ä. umzusteigen.
Aber bevor jetzt jeder einfach nur seine Gewichte in Lib XYZ trainiert und dann im worst-case noch den Code 1:1 klaut:
Nein trainieren mit anderen Frameworks ist nicht erlaubt. Wenn ihr Lust habt dürft ihr aber natürlich gerne Spaßeshalber mit Tensorflow o.ä. auf den Daten rumwerkeln (nach dem Turnier). Die Seite wird noch ein ganzes Stück online bleiben. Da könnt ihr euch also danach je nach belieben auslassen. ![]()
So die zwei versprochenen Datensätze sind auf StudOn, ebenso wie der Link zum Online-Score-Board. Alles zu finden unter “KI2 - Turnier” auf StudOn.
Außerdem habe ich eine Main-File hochgeladen, die zeigt wie man die Datensätze einliest und rausschreibt, ebenso wie eine “neue” DataReader.java und DataWriter.java Datei.
Die Ergebnisse im Scoreboard von mir auf der Website sind Ergebnisse, die man definitiv schlagen kann, aber trotzdem nicht “einfach so” schlagen zu schlagen sind.
Das heißt wer da drüber kommt hat schon definitiv echt ein gutes Framework gebastelt.
Eine kurze Anmerkung noch:
Das sinnvollste ist es natürlich sein Neuronales Netz auszubauen und zu verbessern, aber man kann natürlich auch andere Sachen einbauen/verbessern, damit man die Performance insgesamt boosted. Das könnte Normalisierungs, Umbau der Datenstrukturen, Clustern, usw. sein. Das effektivste ist aber in meinen Augen 70-80% der Zeit ins Netz zu stecken, weil man damit automatisch bei allen 3 Datensätzen gut mit dabei ist und nicht seinen Code auf einen Satz optimiert.
Wie bereits erwähnt sind jedoch alle Libraries, die nicht im Standard zu finden sind, nicht erlaubt.
Auch könnt ihr theoretisch andere Programmiersprachen benutzen. Aber da kann ich euch dann wenig helfen und natürlich müsst ihr dann das ganze Lesen/Schreiben der Daten u.ä. nachbauen, wird sich also wahrscheinlich nicht lohnen. Aber wenn jemand unbedingt darauf Lust hat, nur zu. ![]()
Edit:
Das Image-Datenset kommt im Laufe des Wochenendes (spätestens Montag). Ich muss da noch etwas dran rumbasteln, so wie es momentan ist gefällt es mir nämlich überhaupt nicht.
So das ImageDataset ist jetzt auch hochgeladen. Ich habe es jedoch etwas „beschnitten“. Im Moment gibt es nur noch folgende Klassen:
Außerdem sind alle Bilder in einer Datei zusammengefasst, das hat mehrere Vorteile, die mir aber alle relativ egal waren.
Der Hauptgrund liegt darin, dass das Datenset so bereits rausgegeben/verteilt wurde. Das heißt ihr seht die konkreten Bilder leider nicht, wäre aber auch etwas doof/unübersichtlich bei rund 50k Bildern (bzw. jetzt rund 30k Bilder). Aber ihr könnt euch natürlich auch Methoden bauen, die das Array in Bilder umwandelt, liegt bei euch. ![]()
Jedenfalls sind knapp 90mb komprimiert schon echt einiges und es wird echt hart werden da „gute Ergebnisse“ hinzubekommen, aber ich bin hochgespannt, die aktuellen Ergebnisse im Scoreboard sehen ja auch besser aus als ich erwartet hatte! ![]()
Edit:
Denkt auch daran den neuen DataReader/Writer runter zu laden.
Gibt es diesmal auch wieder „normale“ Übungspunkte für alle, die was halbwegs Sinnvolles abgeben?
Gut, dass dus ansprichst, ich sollte da noch eine E-Mail rumschicken.
Bonuspunkte gibt es dafür besser als die Baseline (also sprich besser als „ich“) zu sein.
Das klingt jetzt erst einmal unfair, aber ich werde nicht wirklich aktiv mit machen und die aktuelle Baseline haben schon 2 von 2 überschritten (zumindest fürs Titanik-Set und beim Rest ist auch schon jemand nahe dran), wobei einer auch noch „Test“ heißt, ich möchte gar nicht wissen was für eine Genauigkeit er hat, wenn die Tests abgeschlossen sind. ![]()
Ich denke gestaffelt macht es am meisten Sinn. Sprich
- 5pkt fürs Titanik Datenset
- 10pkt fürs Traveltime Datenset
- 25pkt fürs Image Datenset
- Punkte für die Top 3, vermutlich auch gestaffelt mit ähnlichen Punkte vergaben wie für die „Baseline“.
Was genau soll man hochladen? Die Predictions?
Bekomme folgende Ausgabe, wenn ich meine titanic predictions hochladen will:
Notice: Undefined offset: 0 in /var/www/html/competition/index.php on line 182
Wrong Password!
1 „Gefällt mir“
Jap die Predictions sollst du hochladen und dafür am besten den DataWriter benutzen, außerdem musst du einen Gruppennamen eingeben und das passende Passwort (falls der Gruppennamen noch nicht existiert einfach das Passwort eingeben welches du in Zukunft benutzen willst). Wenn „wrong password“ kommt hast du relativ sicher einen Gruppennamen eingegeben, der schon vergeben ist und dementsprechend schon mit einem Passwort versehen.
Ich schau aber mal eben fix ins website-backend, ob ich irgendwas offensichtliches o.ä. erkennen kann.
Edit:
Hast du bei den Radioboxen oben sicher das Titanik-Datenset ausgewählt? Probiers einfach nochmal. Falls das Problem trotzdem weiterhin auftritt, sag bitte Bescheid.
Edit2:
Eventuell machen Leerzeichen Probleme? Ich weiß gerade nicht, ob mein Framework das im Hintergrund werkelt standardmäßig die Namen mit Leerzeichen erlaubt, könnte auch daran liegen. So wie es aussieht könnte es daran liegen, ich bessere das mal eben aus.
Edit3:
Der Fehler lag tatsächlich wo anders, danke fürs drauf aufmerksam machen, jetzt sollte es gehen sowohl mit Leerzeichen als auch ohne, usw.
Jo hat geklappt, danke!
Vllt. hab ich die Mail oder Satz im Forum dazu übersehen: Bis wann ist Deadline für das Happening und wann ist “ultimativer Deathmatch” in einer Vorlesung/Übung?
Die Deadline ist Dienstag 24.07.17 23:59.
Ultimatives Deathmatch gibt es so direkt nicht. Die Uebungen naechste Woche werden dafuer genutzt um coole/interessante Ideen/Umsetzungen durchzugehen.
Aber der zweite Datensatz wird am Freitag Abend geteilt, das heist dafuer habt ihr dann Sa+So+Mo+Di Zeit und dementsprechend ist das dann auch „das Deathmatch“. Ein richtiges Deathmatch gibt es so gesehen ja nicht, weil „aktives Vergleichen“ relativ schwer geht. Es spielen ja keine KIs direkt gegeneinander, sondern die Rangliste entscheidet ueber die Gewinner.
Diejenigen 3 Personen, die am Montag morgen die hoechste Wertung auf dem zweiten Datensatz haben, diejenigen Personen kriegen dann auch Bonuspunkte.
Wobei eine Staffelung der Punkte wie folgt aussieht:
-
Platz Titanik: 15 pkt
-
Platz Titanik: 10 pkt
-
Platz Titanik: 5 pkt
-
Platz Traveltime: 20 pkt
-
Platz Traveltime: 15 pkt
-
Platz Traveltime: 10 pkt
-
Platz Image-Dataset: 30 pkt
-
Platz Image-Dataset: 25 pkt
-
Platz Image-Dataset: 15 pkt
Bei der Bestimmung der jeweiligen Gewinner, ist es wichtig, dass die Baseline auch mit reinzaehlt. Wenn also die Baseline beim Image-Dataset Platz #1 ist, dann gibt es halt keine 30pkt fuer irgendjemanden. ![]()
Diejenigen, die ueber die Baseline kommen, bekommen folgende Bonus-Punkte:
Titanik: 5pkt
Traveltime: 10pkt
Image-Dataset: 15pt
Ueber die Baseline kommen beim Titanikset und beim Traveltimeset sollte gut moeglich sein, das Image-Set duerfet hart werden, aber bei weitem nicht unmoeglich (momentane state-of-the-art methoden haben 96% Genauigkeit beim Image-Datenset).
diesen tag gibt es nicht
Error: Day not found! Ups 25.07 war gemeint x)
Kurze Bitte: Wäre jemand so lieb und schreibt mal kurz eine Zeile, wie die Testergebnisse formatiert sein sollen? =) Mache den Spaß in python und habe jetzt intuitiv das Test Resultats File so formatiert wie das Trainingsdaten File, also in der ersten Zeile so:
0|3|male|2|4|1|29.125
Allerdings kriege ich dann beim hochladen ein:
Fatal error: Uncaught Error: Unsupported operand types in /var/www/html/competition/index.php:107 Stack trace: #0 /var/www/html/competition/index.php(236): accuracy(Array, Array, 0) #1 {main} thrown in /var/www/html/competition/index.php on line 107
Error…
Ich danke euch und entschuldige mich für die billige Bitte
In der ersten Spalte der Testausgabe steht die Nummer des Datums und in der zweiten Spalte die Prediction bzw. in den folgenden Spalten alle Predictions (wenn es mehrere gibt).
Die Nummer das jeweiligen Datums ist genau die Zeile im Testdatensatz des Datums.
Ich danke dir!
1 „Gefällt mir“