Disclaimer: Dieser Thread wurde aus dem alten Forum importiert. Daher werden eventuell nicht alle Formatierungen richtig angezeigt. Der ursprüngliche Thread beginnt im zweiten Post dieses Threads.
4. Normalisierung
Hallo,
ich hätte noch eine kleine Frage zur 4. Normalisierung. Es heißt ja, dass eine Relation R in 4. Normalform (NF) ist, wenn für jede nicht-triviale mehrwertige Abhängigkeit x ->-> A in R gilt, dass X Superschlüssel von R ist. Dieses x ->-> A bedeutet wahrscheinlich, dass ein X mehrere A-Werte haben kann? Warum muss X Superschlüssel der ganzen Relation sein?
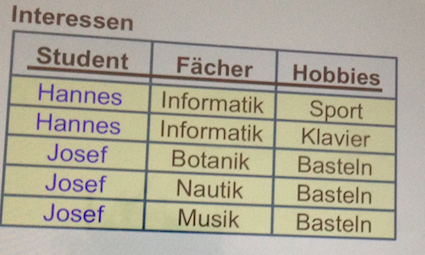
In den Folien 6-34 ist ja ein Beispiel zusehen, bei dem der Primärschlüssel aus der Spalte Student, Fächer und Hobbies zusammengesetzt ist. Ein Student kann mehrere Fächer studieren und auch mehrere Hobbies ausüben. (siehe Anhang Bild 4NFNicht)
Wir haben dann diese Relation in 2 Relationen aufgelöst, in denen jeweils der Student sowie das Fach / Hobby dann den Primärschlüssel darstellen. An dieser Stelle verstehe ich nicht, warum “Student” hier der Superschlüssel der neuen Relationen sein soll, da Student allein ja nicht einmal ein Schlüsselkandidat ist?
Ich habe die Vermutung, dass es zu Problemen kommt, wenn man für Josef, der Botanik, Nautik und Musik studiert, ein 2. Hobby also abgesehen von Basteln auch Radfahren hinzufügen möchte, da man dann ganz schön viel Redundanz hat, welche man vermeidet, wenn man es in 2 Tabellen gliedert. (soweit richtig?)
Meine Frage wäre nun, wie man z.B. in der Klausur erkennen soll, ob es eine mehrwertige Abhängigkeit gibt. Steht das in der Fragestellung dabei oder soll man es an der Extension der Relation ablesen?
Ich hoffe ich habe die 4. NF richtig verstanden. ![]()
Vielen Dank für eure Hilfe!
froschigon
Attachment:
4NfNicht.png: https://fsi.cs.fau.de/unb-attachments/post_149580/4NfNicht.png
{kind=link}
Prinzipiell lassen sich die Normalformen in drei Kategorien einteilen:
1.) Nur auf “Attributsform” bezogen.
2.) Auf die trivialen Abhängigkeiten bezogen.
3.) Auf mehrwertige Abhängigkeiten bezogen.
Zu 1 gehört nur die 1. Normalform, zu 2. die 2. Normalform bis BCNF, zu 3. die 4. und 5. Normalform (Letztere spielt für uns keine Rolle).
- NF: Eliminierung partieller Abhängigkeiten. (Impliziert 1. NF)
- NF: Sicherstellen, das es keine transitive Abhängigkeit zwischen SK und Nicht-Schlüsselattributen. (Impliziert auch 2. NF)
BCNF: Jede Determinante einer FA ist selbst Superschlüssel. (Impliziert 3. NF).
Oder kurz zum Unterschied über BCNF - 3. NF ausgedrückt: In der 3. NF können Informationen doppelt vorkommen, in der BCNF nicht!
Warum ist das wichtig? Die 4. NF impliziert das Vorhandensein der BCNF. Während wir uns aber vorher nur um Informationen INNERHALB von Relationen gekümmert haben, geht es nun um die Frage, ob N-äre Beziehungen korrekt modelliert wurden (Also stehen mehr als 2 Tabellen gleichzeitig in Beziehung). Verhindert werden soll so, dass es innerhalb einer Relation mehrere 1:n oder N:M-Beziehungen zu einem Schlüsselwert gibt, die thematisch nichts miteinander zu tun haben. Anders ausgedrückt: Es gibt mind. 3 Attribute, nennen wir sie A, B, C. A bestimmt mehrere Werte von B und A bestimmt mehrere Werte von C. B und C sind hingegen unabhängig voneinander.
Im Beispiel gibt es Student, Hobbies und das Fach. Student bestimmt mehrere Werte von “Hobbies” und mehrere Werte von “Fächer”. Das ist hier die mehrwertige Abhängigkeit, die gemeint ist. Wohingegen von den “Hobbies” keine Rückschlüsse auf das “Fach” möglich sind, da sie beide unabhängig voneinander sind. Daher muss hier aufgespalten werden, nämlich einmal in Informationen über die “Person” Student (Und seine Hobbies), einmal über seine “Berufung” und den dazu gehörigen Fächern. Erst dann befindet sich die Relation in 4. NF.
Vielen Dank für deine Antwort. Ich hätte aber bzgl. der Klausur noch eine kleine Frage. In der Klausur sind ja immer vollständige Extensionen einer Relation gegeben, wobei die Spaltennamen einer Relation ja ziemlich ohne Semantik z.B. A, B, C sind.
A B C (ABC ist Primärschlüssel)
h i b
h i m
c n t
c b t
c p t
Wie kann ich an einer solchen Extension erkennen, ob diese Relation in der 4. NF ist? Ist es korrekt, dass wenn die letzte Zeile c p t anders, nämlich c p j, lautet, dass die Tabelle weiterhin auch nicht in 4. NF ist?
Grundsätzlich glaube ich, das dir der Begriff “mehrwertige Abhängigkeit” nicht geläufig ist; das ist nichts anderes als eine aufgelöste 1. NF. Nehmen wir an, du wolltest eintragen, das h mehrere Cs hat (Hier: b, m): So musst du dieses in mehrere Zeilen eintragen. 1. NF: Attributwerte sind atomar. Eine mehrwertige Abhängigkeit ist nicht mehr trivial, wenn es noch andere Attribute gibt und (z.B. hier) die Attribute von C nicht in A enthalten sind.
Wie gesagt: Wir reden hierbei nicht mehr von “einfachen” Abhängigkeiten sondern von Mehrfachen.
Deswegen stimmt es auch nicht, das bei einer Umbenennung der letzten Zeile in c, p, j die Abähngigkeit so wäre wie vorher; du hast hierbei in den ersten beiden Zeilen zwei gleiche Werte (h, i), um darzustellen, das sich in der dritten Spalte der Wert ändert; in den letzten drei Zeilen hingegen in der ersten und der dritten Spalte gleiche Werte, um eine Änderung in der zweiten Spalte darzustellen. Wäre es in der letzten Zeile c, p, j, (vorausgesetzt wieder, die Extension sei vollständig) wäre damit klar, das A nicht länger mehrere Werte in C bestimmt. Dementsprechend wäre eine der Voraussetzungen nicht gegeben (A bestimmt mehrere Werte von B und A bestimmt mehrere Werte von C). Denn dann würde aus c in A einmal t, einmal j folgen. Somit würde c keinen Wert in C bestimmen, h sowieso nicht. Dementsprechend kann sie in der 4. NF sein.
Daraus folgt, das A mehrere Werte in B und mehrere Werte in C bestimmt. Trotzdem ist ersichtlich, das B und C unabhängig voneinander sind, auch wenn du die Extension so beschreibst.
Vielen Dank! Das war mein Denkfehler. ![]()